# Uncomment to run the notebook in Colab
# ! pip install -q "wax-ml[complete]@git+https://github.com/eserie/wax-ml.git"
# ! pip install -q --upgrade jax jaxlib==0.1.70+cuda111 -f https://storage.googleapis.com/jax-releases/jax_releases.html
%matplotlib inline
import io
import warnings
from collections import defaultdict
from pathlib import Path
from typing import Any, Callable, NamedTuple, Optional, TypeVar
import haiku as hk
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import numpy as onp
import optax
import pandas as pd
import plotnine as gg
import requests
from sklearn.preprocessing import MinMaxScaler
from tqdm.auto import tqdm
from wax.accessors import register_wax_accessors
from wax.compile import jit_init_apply
from wax.encode import Encoder
from wax.modules import Buffer, FillNanInf, Lag, RollingMean
from wax.unroll import unroll
print("jax backend {}".format(jax.lib.xla_bridge.get_backend().platform))
jax.devices()
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
jax backend cpu
[<jaxlib.xla_extension.Device at 0x14ade9f70>]
🔭 Reconstructing the light curve of stars with LSTM 🔭¶
![]()
Let’s take a walk through the stars…
This notebook is based on the study done in this post by Christophe Pere and the notebook available on the authors’s github.
We will repeat this study on starlight using the LSTM architecture to predict the observed light flux through time.
Our LSTM implementation is based on this notebook from Haiku’s github repository.
We’ll see how to use WAX-ML to ease the preparation of time series data stored in dataframes and having Nans before calling a “standard” deep-learning workflow.
Disclaimer¶
Despite the fact that this code works with real data, the results presented here should not be considered as scientific knowledge insights, to the knowledge of the authors of WAX-ML, neither the results nor the data source have been reviewed by an astrophysics pair.
The purpose of this notebook is only to demonstrate how WAX-ML can be used when applying a “standard” machine learning workflow, here LSTM, to analyze time series.
Download the data¶
register_wax_accessors()
# Parameters
STAR = "007609553"
SEQ_LEN = 64
BATCH_SIZE = 8
TRAIN_SIZE = 2 ** 16
NUM_EPOCHS = 10
NUM_STARS = None
RECORD_FREQ = 100
TOTAL_LEN = None
TRAIN_DATE = "2016"
CACHE_DIR = Path("./cached_data/")
%%time
filename = CACHE_DIR / "kep_lightcurves.parquet"
try:
raw_dataframe = pd.read_parquet(open(filename, "rb"))
print(f"data read from {filename}")
except FileNotFoundError:
# Downloading the csv file from Chrustioge Pere GitHub account
download = requests.get(
"https://raw.github.com/Christophe-pere/Time_series_RNN/master/kep_lightcurves.csv"
).content
raw_dataframe = pd.read_csv(io.StringIO(download.decode("utf-8")))
# set date index
raw_dataframe.index = pd.Index(
pd.date_range("2009-03-07", periods=len(raw_dataframe.index), freq="h"),
name="time",
)
# save dataframe locally in CACHE_DIR
CACHE_DIR.mkdir(exist_ok=True)
raw_dataframe.to_parquet(filename)
print(f"data saved in {filename}")
data read from cached_data/kep_lightcurves.parquet
CPU times: user 55.3 ms, sys: 32.2 ms, total: 87.5 ms
Wall time: 40.8 ms
# shortening of data to speed up the execution of the notebook in the CI
if TOTAL_LEN:
raw_dataframe = raw_dataframe.iloc[:TOTAL_LEN]
Let’s visualize the description of this dataset:
raw_dataframe.describe().T.to_xarray()
<xarray.Dataset>
Dimensions: (index: 52)
Coordinates:
* index (index) object '001430305_orig' ... '011611275_res'
Data variables:
count (index) float64 6.48e+04 5.674e+04 ... 5.673e+04 5.673e+04
mean (index) float64 6.776e+04 -0.2265 0.01231 ... 0.001437 0.004351
std (index) float64 1.363e+03 15.42 15.27 12.45 ... 4.648 6.415 4.904
min (index) float64 6.529e+04 -123.3 -75.59 ... -20.32 -31.97 -20.89
25% (index) float64 6.619e+04 -9.488 -9.875 ... -3.269 -4.281 -3.279
50% (index) float64 6.806e+04 -0.3476 0.007812 ... 0.007812 -0.06529
75% (index) float64 6.882e+04 8.988 10.02 8.092 ... 2.872 4.277 3.213
max (index) float64 7.021e+04 128.7 72.31 69.34 ... 26.53 30.94 29.45- index: 52
- index(index)object'001430305_orig' ... '011611275_...
array(['001430305_orig', '001430305_rscl', '001430305_diff', '001430305_res', '001724719_orig', '001724719_rscl', '001724719_diff', '001724719_res', '005209845_orig', '005209845_rscl', '005209845_diff', '005209845_res', '007596240_orig', '007596240_rscl', '007596240_diff', '007596240_res', '007609553_orig', '007609553_rscl', '007609553_diff', '007609553_res', '008241079_orig', '008241079_rscl', '008241079_diff', '008241079_res', '008247770_orig', '008247770_rscl', '008247770_diff', '008247770_res', '009345933_orig', '009345933_rscl', '009345933_diff', '009345933_res', '009347009_orig', '009347009_rscl', '009347009_diff', '009347009_res', '009349482_orig', '009349482_rscl', '009349482_diff', '009349482_res', '009349757_orig', '009349757_rscl', '009349757_diff', '009349757_res', '010024701_orig', '010024701_rscl', '010024701_diff', '010024701_res', '011611275_orig', '011611275_rscl', '011611275_diff', '011611275_res'], dtype=object)
- count(index)float646.48e+04 5.674e+04 ... 5.673e+04
array([64795., 56736., 50906., 50906., 64795., 59620., 55595., 55595., 54969., 49817., 45968., 45968., 64792., 60090., 56475., 56475., 64793., 50829., 45782., 45782., 64794., 54544., 50508., 50508., 64793., 58882., 54562., 54562., 64797., 60963., 58136., 58136., 64793., 60579., 57363., 57363., 64793., 61021., 58217., 58217., 64793., 60789., 57793., 57793., 51732., 47598., 44189., 44189., 64792., 60245., 56728., 56728.]) - mean(index)float646.776e+04 -0.2265 ... 0.004351
array([ 6.77637640e+04, -2.26476394e-01, 1.23063833e-02, 4.76521496e-02, 3.48858739e+04, -2.60434079e-01, -6.42200288e-04, 8.80227557e-03, 5.39107577e+03, 7.03697184e-03, -1.60903054e-02, -2.92293746e-02, 1.63334514e+04, -1.51960427e-01, -8.43860668e-03, -1.19774483e-02, 2.13926602e+04, -4.33682072e-01, 8.27861864e-03, 9.57967429e-03, 5.67090880e+04, -3.64663429e-01, -2.67114244e-03, 6.54392308e-03, 2.91100849e+04, -8.32231802e-02, -3.71574138e-03, -2.05330738e-02, 7.19740760e+03, -3.04019017e-02, -7.65547327e-04, 1.39132462e-03, 7.52192300e+03, -1.21187104e-01, 9.12380197e-03, 1.61813028e-02, 8.94735741e+03, -9.96904951e-02, 4.80096959e-03, 1.14104920e-02, 1.17224306e+04, -1.00470553e-01, 9.67554394e-03, 2.29960238e-02, 6.68149138e+04, -1.87700299e-01, -1.28047280e-02, -6.32266111e-03, 1.29621460e+04, -1.57874003e-01, 1.43721396e-03, 4.35098594e-03]) - std(index)float641.363e+03 15.42 ... 6.415 4.904
array([1362.5144182 , 15.42150384, 15.27052111, 12.44643235, 1528.19752763, 10.91976669, 11.1893542 , 8.62113287, 204.78780872, 20.19896883, 5.84919971, 4.6135537 , 535.20007192, 4.91307619, 6.8001509 , 5.21149265, 660.12491961, 153.47838423, 7.95784752, 6.83305069, 999.65408025, 15.75699475, 11.27259006, 8.82762192, 893.28598443, 11.31868477, 9.1138139 , 7.4161203 , 432.80513443, 21.70344223, 5.70210104, 4.54982055, 179.82292187, 19.17226962, 5.43930877, 4.37342724, 177.04591928, 4.67562213, 6.00262878, 4.61455226, 272.81579415, 11.3153307 , 6.40128184, 5.00633304, 2252.26388443, 89.94131559, 11.75971874, 10.21930995, 325.0546655 , 4.64757018, 6.4154822 , 4.9035335 ]) - min(index)float646.529e+04 -123.3 ... -31.97 -20.89
array([ 6.52850664e+04, -1.23261443e+02, -7.55937500e+01, -5.81310419e+01, 3.19670938e+04, -6.66089800e+01, -5.55937500e+01, -3.80387838e+01, 4.95582812e+03, -9.06898032e+01, -3.17832031e+01, -2.36347987e+01, 1.54332500e+04, -3.66425336e+01, -3.57548828e+01, -3.61389287e+01, 2.00126504e+04, -6.94903224e+02, -3.80410156e+01, -3.14954085e+01, 5.48705469e+04, -8.74110917e+01, -5.62773438e+01, -5.71788510e+01, 2.72978945e+04, -6.94690785e+01, -4.73476562e+01, -3.98079267e+01, 6.30219580e+03, -1.03889194e+02, -3.24965820e+01, -2.49301202e+01, 7.22198877e+03, -8.07118370e+01, -2.76318359e+01, -1.87084745e+01, 8.58008008e+03, -2.36194950e+01, -2.88779297e+01, -2.23368082e+01, 1.11858164e+04, -6.24034405e+01, -3.32412109e+01, -2.65777562e+01, 6.34323672e+04, -3.55021741e+02, -5.77968750e+01, -7.86537031e+01, 1.23135605e+04, -2.03195390e+01, -3.19687500e+01, -2.08865991e+01]) - 25%(index)float646.619e+04 -9.488 ... -4.281 -3.279
array([ 6.61889219e+04, -9.48833642e+00, -9.87500000e+00, -8.08656653e+00, 3.32582266e+04, -7.31995398e+00, -7.44335938e+00, -5.79592451e+00, 5.18955225e+03, -9.56397223e+00, -3.89270020e+00, -3.11812362e+00, 1.58437983e+04, -3.44825902e+00, -4.50830078e+00, -3.52359963e+00, 2.07200391e+04, -7.54642556e+01, -5.27343750e+00, -4.56884892e+00, 5.59803770e+04, -1.02040155e+01, -7.57812500e+00, -5.93617727e+00, 2.81871973e+04, -7.12718836e+00, -6.01953125e+00, -4.90452721e+00, 6.65427344e+03, -1.23264574e+01, -3.74560547e+00, -3.03522067e+00, 7.42203711e+03, -1.13228045e+01, -3.61962891e+00, -2.91987469e+00, 8.78827148e+03, -3.17652362e+00, -3.98632812e+00, -3.08491497e+00, 1.15134297e+04, -6.10318459e+00, -4.21875000e+00, -3.29996354e+00, 6.49962314e+04, -5.62104609e+01, -7.89062500e+00, -6.86189833e+00, 1.28410632e+04, -3.26949598e+00, -4.28125000e+00, -3.27908045e+00]) - 50%(index)float646.806e+04 -0.3476 ... -0.06529
array([ 6.80613828e+04, -3.47636218e-01, 7.81250000e-03, -1.30725999e-02, 3.53564023e+04, -9.16894810e-02, -3.51562500e-02, -2.89893356e-02, 5.41613721e+03, 1.46219949e-01, -5.78613281e-02, -9.43597722e-02, 1.65516709e+04, -2.64416689e-01, 2.73437500e-02, -9.33119760e-02, 2.14401523e+04, 1.14545608e+01, 2.14843750e-02, -5.92623226e-02, 5.67837734e+04, 8.92652675e-02, 1.95312500e-03, -7.25704027e-02, 2.95458281e+04, 4.87577712e-02, -4.49218750e-02, -1.00367284e-01, 7.25929248e+03, -2.94537715e-01, 3.34472656e-02, -2.26939366e-02, 7.45421924e+03, -3.65075272e-01, -1.66015625e-02, -4.78969335e-02, 8.95055371e+03, -1.40979344e-01, 7.81250000e-03, -1.58822255e-02, 1.16602783e+04, 2.74758582e-01, 2.73437500e-02, -4.15869687e-02, 6.58943555e+04, 3.32494254e+00, 4.68750000e-02, -5.63888776e-02, 1.29597114e+04, -2.24671520e-01, 7.81250000e-03, -6.52851501e-02]) - 75%(index)float646.882e+04 8.988 ... 4.277 3.213
array([6.88189727e+04, 8.98839136e+00, 1.00234375e+01, 8.09175077e+00, 3.61145820e+04, 7.01429305e+00, 7.48437500e+00, 5.69826563e+00, 5.53317725e+03, 1.00475793e+01, 3.87048340e+00, 2.98923215e+00, 1.68310957e+04, 3.02806213e+00, 4.49414062e+00, 3.38630625e+00, 2.20209531e+04, 9.08799796e+01, 5.26367188e+00, 4.52717869e+00, 5.74483965e+04, 1.01837346e+01, 7.51171875e+00, 5.81439607e+00, 2.99188320e+04, 7.15369426e+00, 6.00732422e+00, 4.81928542e+00, 7.52007275e+03, 1.29233935e+01, 3.76867676e+00, 2.95097962e+00, 7.65798096e+03, 1.08133591e+01, 3.61523438e+00, 2.87012749e+00, 9.08583008e+03, 2.94619654e+00, 3.98046875e+00, 3.03713233e+00, 1.19144434e+04, 6.53949167e+00, 4.25976562e+00, 3.31653085e+00, 6.81768262e+04, 5.91546280e+01, 7.77343750e+00, 6.74722831e+00, 1.31409404e+04, 2.87210558e+00, 4.27661133e+00, 3.21300974e+00]) - max(index)float647.021e+04 128.7 ... 30.94 29.45
array([7.02122031e+04, 1.28660432e+02, 7.23125000e+01, 6.93417611e+01, 3.75573242e+04, 4.79886762e+01, 8.00234375e+01, 6.16484304e+01, 6.00489502e+03, 9.13358716e+01, 2.45039062e+01, 2.61494406e+01, 1.73261172e+04, 2.35996818e+01, 3.72900391e+01, 2.62028292e+01, 2.24849180e+04, 3.82495214e+02, 3.95625000e+01, 3.61686737e+01, 5.90490898e+04, 7.62124556e+01, 5.41562500e+01, 5.42089099e+01, 3.03895098e+04, 6.19293590e+01, 4.28691406e+01, 4.45521063e+01, 7.83280371e+03, 7.73476225e+01, 2.73188477e+01, 2.46408888e+01, 8.00235156e+03, 6.99670019e+01, 3.19765625e+01, 2.73471557e+01, 9.59054297e+03, 2.72015177e+01, 2.51455078e+01, 2.51618206e+01, 1.22767207e+04, 4.38635401e+01, 3.68515625e+01, 3.04471056e+01, 7.25150000e+04, 3.21070047e+02, 6.51328125e+01, 5.87010158e+01, 1.39579814e+04, 2.65332384e+01, 3.09394531e+01, 2.94483002e+01])
stars = raw_dataframe.columns
stars = sorted(list(set([i.split("_")[0] for i in stars])))
print(f"The number of stars available is: {len(stars)}")
print(f"star identifiers: {stars}")
The number of stars available is: 13
star identifiers: ['001430305', '001724719', '005209845', '007596240', '007609553', '008241079', '008247770', '009345933', '009347009', '009349482', '009349757', '010024701', '011611275']
dataframe = raw_dataframe[[i + "_rscl" for i in stars]].rename(
columns=lambda c: c.replace("_rscl", "")
)
dataframe.columns.names = ["star"]
dataframe.shape
(71427, 13)
if NUM_STARS:
columns = dataframe.columns.tolist()
columns.remove(STAR)
dataframe = dataframe[[STAR] + columns[: NUM_STARS - 1]]
Rolling mean¶
We will smooth the data by applying a rolling mean with a window of 100 periods.
Count nan values¶
But before since the dataset has some nan values, we will extract few statistics about the density of nan values in windows of size 100.
It will be the occasion to show a usage of the wax.modules.Buffer module with the format_outputs=False
option for the dataframe accessor .wax.stream.
Let’s apply the Buffer module to the data:
buffer, _ = dataframe.wax.stream(format_outputs=False).apply(lambda x: Buffer(100)(x))
assert isinstance(buffer, jnp.ndarray)
Equivalently, we can use wax unroll function.
buffer = unroll(lambda x: Buffer(100)(x))(jax.device_put(dataframe.values))
Let’s describe the statistic of nans with pandas:
count_nan = jnp.isnan(buffer).sum(axis=1)
pd.DataFrame(onp.array(count_nan)).stack().describe().astype(int)
count 928551
mean 20
std 27
min 0
25% 5
50% 8
75% 19
max 100
dtype: int64
Computing the rolling mean¶
We will choose a min_periods of 5 in order to keep at leas 75% of the points.
%%time
dataframe_mean, _ = dataframe.wax.stream().apply(
lambda x: RollingMean(100, min_periods=5)(x)
)
CPU times: user 262 ms, sys: 9.48 ms, total: 272 ms
Wall time: 270 ms
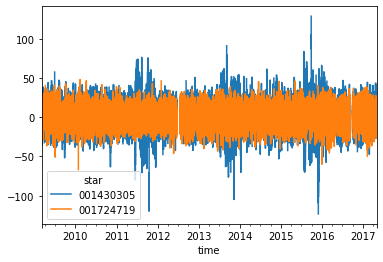
dataframe.iloc[:, :2].plot()
<AxesSubplot:xlabel='time'>
Forecasting with Machine Learning¶
We need two forecast in this data, if you look with attention you’ll see micro holes and big holes.
T = TypeVar("T")
class Pair(NamedTuple):
x: T
y: T
class TrainSplit(NamedTuple):
train: T
validation: T
gg.theme_set(gg.theme_bw())
warnings.filterwarnings("ignore")
plt.rcParams["figure.figsize"] = 18, 8
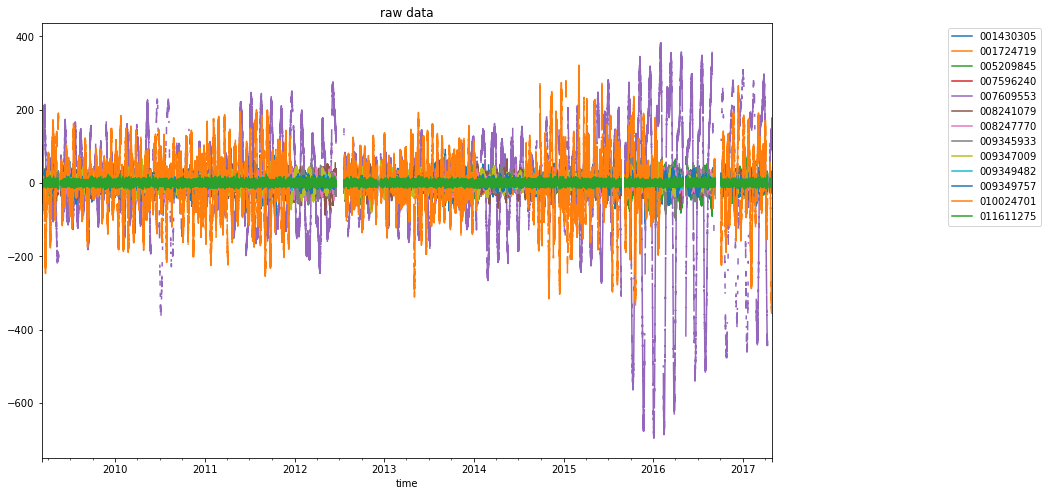
fig, (ax, lax) = plt.subplots(ncols=2, gridspec_kw={"width_ratios": [4, 1]})
dataframe.plot(ax=ax, title="raw data")
ax.legend(bbox_to_anchor=(0, 0, 1, 1), bbox_transform=lax.transAxes)
lax.axis("off")
(0.0, 1.0, 0.0, 1.0)
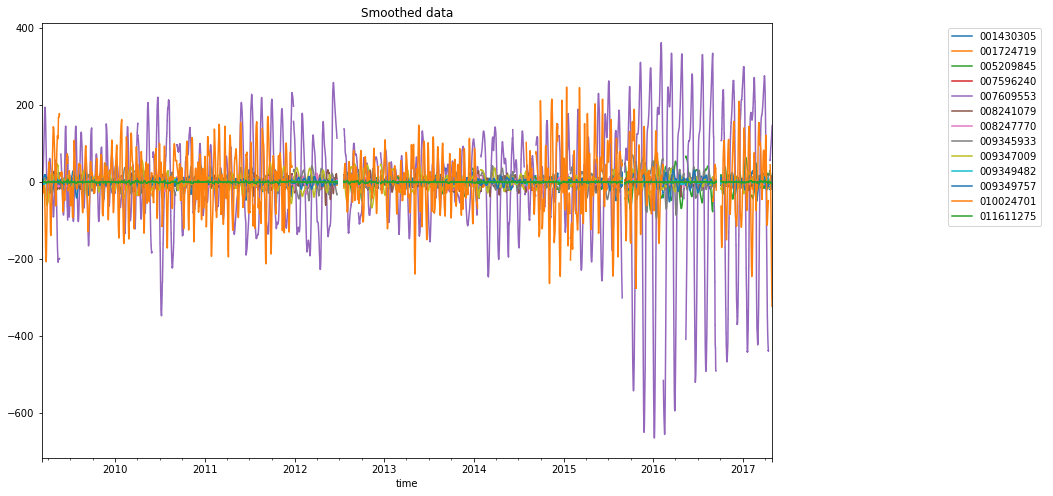
plt.rcParams["figure.figsize"] = 18, 8
fig, (ax, lax) = plt.subplots(ncols=2, gridspec_kw={"width_ratios": [4, 1]})
dataframe_mean.plot(ax=ax, title="Smoothed data")
ax.legend(bbox_to_anchor=(0, 0, 1, 1), bbox_transform=lax.transAxes)
lax.axis("off")
# -
(0.0, 1.0, 0.0, 1.0)
Normalize data¶
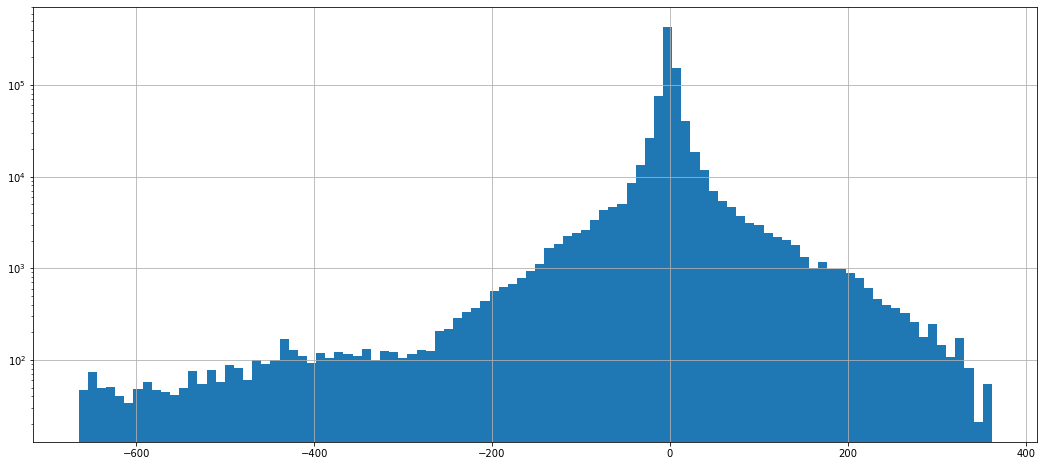
dataframe_mean.stack().hist(bins=100, log=True)
<AxesSubplot:>
def min_max_scaler(values: pd.DataFrame, output_format: str = "dataframe") -> Encoder:
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(values)
index = values.index
columns = values.columns
def encode(dataframe: pd.DataFrame):
nonlocal index
nonlocal columns
index = dataframe.index
columns = dataframe.columns
array_normed = scaler.transform(dataframe)
if output_format == "dataframe":
return pd.DataFrame(array_normed, index, columns)
elif output_format == "jax":
return jnp.array(array_normed)
else:
return array_normed
def decode(array_scaled):
value = scaler.inverse_transform(array_scaled)
if output_format == "dataframe":
return pd.DataFrame(value, index, columns)
else:
return value
return Encoder(encode, decode)
scaler = min_max_scaler(dataframe_mean)
dataframe_normed = scaler.encode(dataframe_mean)
assert (scaler.decode(dataframe_normed) - dataframe_mean).stack().abs().max() < 1.0e-4
dataframe_normed.stack().hist(bins=100)
<AxesSubplot:>
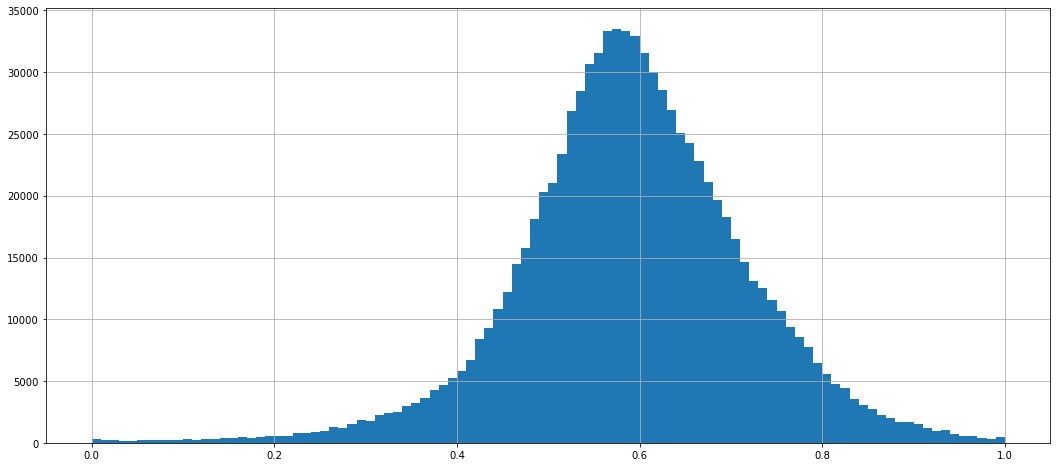
Prepare train / validation datasets¶
def split_feature_target(
dataframe,
look_back=SEQ_LEN,
shuffle=True,
stack=True,
min_periods_ratio: float = 0.8,
rng=None,
) -> Pair:
def prepare_xy(data):
buffer = Buffer(look_back + 1)(data)
x = buffer[:-1]
y = buffer[-1]
return x, y
def prepare_xy(data):
y = Buffer(look_back)(data)
x = Lag(1)(y)
return x, y
x, y = unroll(prepare_xy)(jax.device_put(dataframe.values))
if shuffle:
if rng is None:
rng = jax.random.PRNGKey(42)
B = x.shape[0]
idx = jnp.arange(B)
idx = jax.random.shuffle(rng, idx)
x = x[idx]
y = y[idx]
if stack:
B, T, F = x.shape
x = x.transpose(1, 0, 2).reshape(T, B * F, 1).transpose(1, 0, 2)
y = y.transpose(1, 0, 2).reshape(T, B * F, 1).transpose(1, 0, 2)
if min_periods_ratio:
T = x.shape[1]
count_nan = jnp.isnan(x).sum(axis=1)
mask = count_nan < min_periods_ratio * T
idx = jnp.where(mask)
x = x[idx[0]]
y = y[idx[0]]
# round Batch size to a power of to
B = x.shape[0]
B_round = int(2 ** jnp.floor(jnp.log2(B)))
print(f"{B} batches rounded to {B_round} batches.")
x = x[:B_round]
y = y[:B_round]
# fillnan by zeros
x, y = hk.testing.transform_and_run(lambda x: FillNanInf()(x))((x, y))
return Pair(x, y)
# split_feature_target(dataframe)
def split_train_validation(
dataframe, train_size, look_back, scaler: Optional[Callable] = None
) -> TrainSplit:
# prepare scaler
train_df = dataframe.iloc[:train_size]
if scaler:
scaler = scaler(train_df)
# prepare train data
if scaler:
train_df = scaler.encode(train_df)
train_xy = split_feature_target(train_df, look_back)
# prepare validation data
valid_size = len(dataframe) - train_size
valid_size = int(2 ** jnp.floor(jnp.log2(valid_size)))
valid_end = int(train_size + valid_size)
valid_df = dataframe.iloc[train_size:valid_end]
if scaler:
valid_df = scaler.encode(valid_df)
valid_xy = split_feature_target(valid_df, look_back)
return TrainSplit(train_xy, valid_xy)
TRAIN_SIZE
65536
print(f"Look at star: {STAR}")
train, valid = split_train_validation(dataframe_normed[[STAR]], TRAIN_SIZE, SEQ_LEN)
Look at star: 007609553
63871 batches rounded to 32768 batches.
3597 batches rounded to 2048 batches.
train[0].shape, train[1].shape, valid[0].shape, valid[1].shape
((32768, 64, 1), (32768, 64, 1), (2048, 64, 1), (2048, 64, 1))
# TRAIN_SIZE, VALID_SIZE = len(train.x), len(valid.x)
print(
f"effective train_size = {len(train.x)}, " f"effective valid size= {len(valid.x)}"
)
effective train_size = 32768, effective valid size= 2048
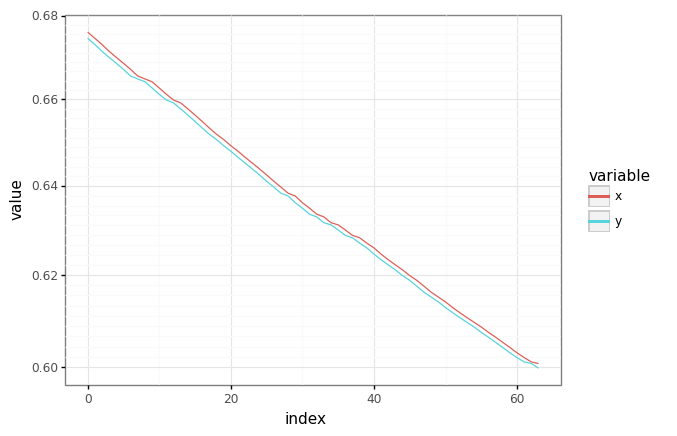
# Plot an observation/target pair.
rng = jax.random.PRNGKey(42)
batch_plot = jax.random.choice(rng, len(train[0]))
df = pd.DataFrame(
{"x": train.x[batch_plot, :, 0], "y": train.y[batch_plot, :, 0]}
).reset_index()
df = pd.melt(df, id_vars=["index"], value_vars=["x", "y"])
plot = (
gg.ggplot(df)
+ gg.aes(x="index", y="value", color="variable")
+ gg.geom_line()
+ gg.scales.scale_y_log10()
)
_ = plot.draw()
Dataset iterator¶
class Dataset:
"""An iterator over a numpy array, revealing batch_size elements at a time."""
def __init__(self, xy: Pair, batch_size: int):
self._x, self._y = xy
self._batch_size = batch_size
self._length = self._x.shape[0]
self._idx = 0
if self._length % batch_size != 0:
msg = "dataset size {} must be divisible by batch_size {}."
raise ValueError(msg.format(self._length, batch_size))
def __next__(self) -> Pair:
start = self._idx
end = start + self._batch_size
x, y = self._x[start:end], self._y[start:end]
if end >= self._length:
print(f"End of the data set (size={end}). Return to the beginning.")
end = end % self._length
assert end == 0 # Guaranteed by ctor assertion.
self._idx = end
return Pair(x, y)
Training an LSTM¶
To train the LSTM, we define a Haiku function which unrolls the LSTM over the input sequence, generating predictions for all output values. The LSTM always starts with its initial state at the start of the sequence.
The Haiku function is then transformed into a pure function through hk.transform, and is trained with Adam on an L2 prediction loss.
def unroll_net(seqs: jnp.ndarray):
"""Unrolls an LSTM over seqs, mapping each output to a scalar."""
# seqs is [T, B, F].
core = hk.LSTM(32)
batch_size = seqs.shape[0]
outs, state = hk.dynamic_unroll(
core, seqs, core.initial_state(batch_size), time_major=False
)
# We could include this Linear as part of the recurrent core!
# However, it's more efficient on modern accelerators to run the linear once
# over the entire sequence than once per sequence element.
return hk.BatchApply(hk.Linear(1))(outs), state
model = jit_init_apply(hk.transform(unroll_net))
@jax.jit
def loss(pred, y):
return jnp.mean(jnp.square(pred - y))
def model_with_loss(x, y):
pred, _ = unroll_net(x)
return loss(pred, y)
class TrainState(NamedTuple):
step: int
params: Any
opt_state: Any
rng: jnp.ndarray
loss: float
def train_model(
model_with_loss: Callable,
train_ds: Dataset,
valid_ds: Dataset,
max_iterations: int = -1,
rng=None,
record_freq=100,
) -> hk.Params:
"""Initializes and trains a model on train_ds, returning the final params."""
opt = optax.adam(1e-3)
model_with_loss = jit_init_apply(hk.transform(model_with_loss))
@jax.jit
def update(train_state, x, y):
step, params, opt_state, rng, _ = train_state
if rng is not None:
(rng,) = jax.random.split(rng, 1)
l, grads = jax.value_and_grad(model_with_loss.apply)(params, rng, x, y)
grads, opt_state = opt.update(grads, opt_state)
params = optax.apply_updates(params, grads)
return TrainState(step + 1, params, opt_state, rng, l)
# Initialize state.
def init():
x, y = next(train_ds)
params = model_with_loss.init(rng, x, y)
opt_state = opt.init(params)
return TrainState(0, params, opt_state, rng, jnp.inf)
def _format_results(records):
records = {key: jnp.stack(l) for key, l in records.items()}
return records
records = defaultdict(list)
train_state = init()
with tqdm(total=max_iterations if max_iterations > 0 else None) as pbar:
while True:
try:
x, y = next(train_ds)
except StopIteration:
return train_state, _format_results(records)
train_state = update(train_state, x, y)
if train_state.step % record_freq == 0:
x, y = next(valid_ds)
if rng is not None:
(rng,) = jax.random.split(rng, 1)
valid_loss = model_with_loss.apply(train_state.params, rng, x, y)
records["step"].append(train_state.step)
records["valid_loss"].append(valid_loss)
records["train_loss"].append(train_state.loss)
pbar.update()
if max_iterations > 0 and train_state.step >= max_iterations:
return train_state, _format_results(records)
%%time
train, valid = split_train_validation(dataframe_normed[[STAR]], TRAIN_SIZE, SEQ_LEN)
train_ds = Dataset(train, BATCH_SIZE)
valid_ds = Dataset(valid, BATCH_SIZE)
train_state, records = train_model(
model_with_loss,
train_ds,
valid_ds,
len(train.x) // BATCH_SIZE * NUM_EPOCHS,
rng=jax.random.PRNGKey(42),
record_freq=RECORD_FREQ,
)
63871 batches rounded to 32768 batches.
3597 batches rounded to 2048 batches.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=2048). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
End of the data set (size=32768). Return to the beginning.
CPU times: user 58.6 s, sys: 371 ms, total: 59 s
Wall time: 58.8 s
# train_state.params
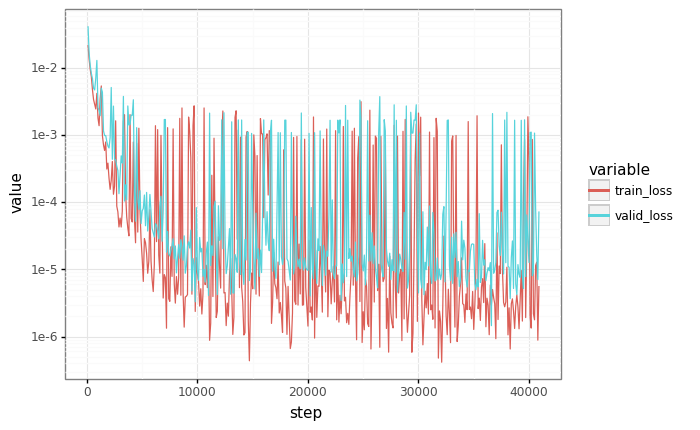
# Plot losses
losses = pd.DataFrame(records)
df = pd.melt(losses, id_vars=["step"], value_vars=["train_loss", "valid_loss"])
plot = (
gg.ggplot(df)
+ gg.aes(x="step", y="value", color="variable")
+ gg.geom_line()
+ gg.scales.scale_y_log10()
)
_ = plot.draw()
Sampling¶
The point of training models is so that they can make predictions! How can we generate predictions with the trained model?
If we’re allowed to feed in the ground truth, we can just run the original model’s apply function.
def plot_samples(truth: np.ndarray, prediction: np.ndarray) -> gg.ggplot:
assert truth.shape == prediction.shape
df = pd.DataFrame(
{"truth": truth.squeeze(), "predicted": prediction.squeeze()}
).reset_index()
df = pd.melt(df, id_vars=["index"], value_vars=["truth", "predicted"])
plot = (
gg.ggplot(df) + gg.aes(x="index", y="value", color="variable") + gg.geom_line()
)
return plot
# Grab a sample from the validation set.
sample_x, sample_y = next(valid_ds)
sample_x = sample_x[:1] # Shrink to batch-size 1.
sample_y = sample_y[:1]
# Generate a prediction, feeding in ground truth at each point as input.
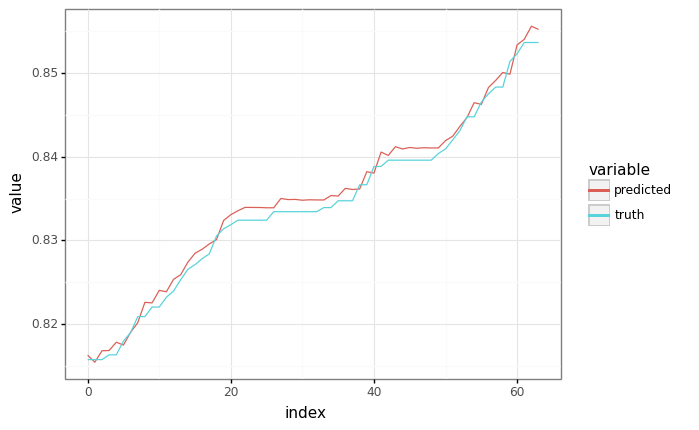
predicted, _ = model.apply(train_state.params, None, sample_x)
plot = plot_samples(sample_y, predicted)
plot.draw()
del sample_x, predicted
Run autoregressively¶
If we can’t feed in the ground truth (because we don’t have it), we can also run the model autoregressively.
def autoregressive_predict(
trained_params: hk.Params,
context: jnp.ndarray,
seq_len: int,
pbar=False,
):
"""Given a context, autoregressively generate the rest of a sine wave."""
ar_outs = []
context = jax.device_put(context)
times = onp.arange(seq_len - context.shape[1] + 1)
if pbar:
times = tqdm(times)
for _ in times:
full_context = jnp.concatenate([context] + ar_outs, axis=1)
outs, _ = model.apply(trained_params, None, full_context)
# Append the newest prediction to ar_outs.
ar_outs.append(outs[:, -1:, :])
# Return the final full prediction.
return outs
sample_x, sample_y = next(valid_ds)
sample_x = sample_x[:1] # Shrink to batch-size 1.
sample_y = sample_y[:1] # Shrink to batch-size 1.
context_length = SEQ_LEN // 8
print(f"context_length = {context_length}")
# Cut the batch-size 1 context from the start of the sequence.
context = sample_x[:, :context_length]
context_length = 8
%%time
# We can reuse params we got from training for inference - as long as the
# declaration order is the same.
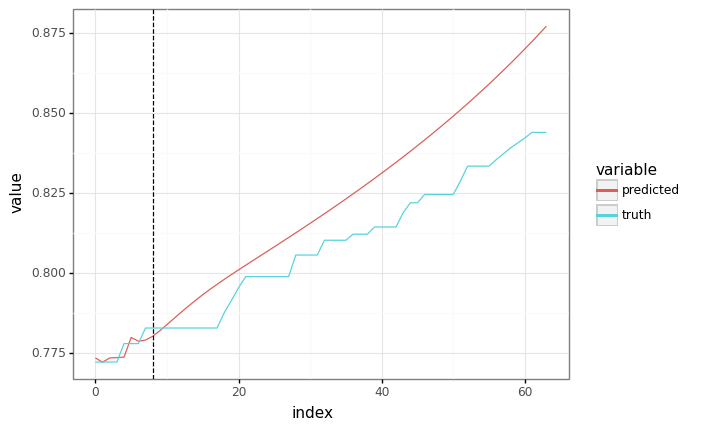
predicted = autoregressive_predict(train_state.params, context, SEQ_LEN, pbar=True)
CPU times: user 7.5 s, sys: 123 ms, total: 7.63 s
Wall time: 7.56 s
sample_y.shape, predicted.shape
((1, 64, 1), (1, 64, 1))
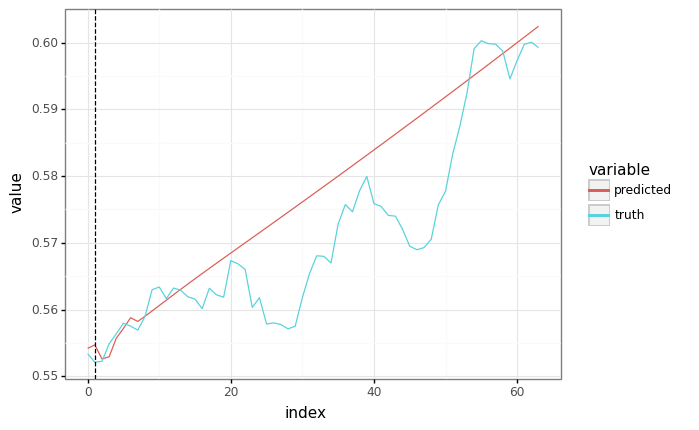
plot = plot_samples(sample_y, predicted)
plot += gg.geom_vline(xintercept=context.shape[1], linetype="dashed")
_ = plot.draw()
Sharing parameters with a different function.¶
Unfortunately, this is a bit slow - we’re doing O(N^2) computation for a sequence of length N.
It’d be better if we could do the autoregressive sampling all at once - but we need to write a new Haiku function for that.
We’re in luck - if the Haiku module names match, the same parameters can be used for multiple Haiku functions.
This can be achieved through a combination of two techniques:
If we manually give a unique name to a module, we can ensure that the parameters are directed to the right places.
If modules are instantiated in the same order, they’ll have the same names in different functions.
Here, we rely on method #2 to create a fast autoregressive prediction.
@hk.transform
def fast_autoregressive_predict_fn(context, seq_len):
"""Given a context, autoregressively generate the rest of a sine wave."""
core = hk.LSTM(32)
dense = hk.Linear(1)
state = core.initial_state(context.shape[0])
# Unroll over the context using `hk.dynamic_unroll`.
# As before, we `hk.BatchApply` the Linear for efficiency.
context_outs, state = hk.dynamic_unroll(
core,
context,
state,
time_major=False,
)
context_outs = hk.BatchApply(dense)(context_outs)
# Now, unroll one step at a time using the running recurrent state.
ar_outs = []
x = context_outs[:, -1, :]
times = range(seq_len - context.shape[1])
for _ in times:
x, state = core(x, state)
x = dense(x)
ar_outs.append(x)
ar_outs = jnp.stack(ar_outs)
ar_outs = ar_outs.transpose(1, 0, 2)
return jnp.concatenate([context_outs, ar_outs], axis=1)
fast_autoregressive_predict = jax.jit(
fast_autoregressive_predict_fn.apply, static_argnums=(3,)
)
%%time
# Reuse the same context from the previous cell.
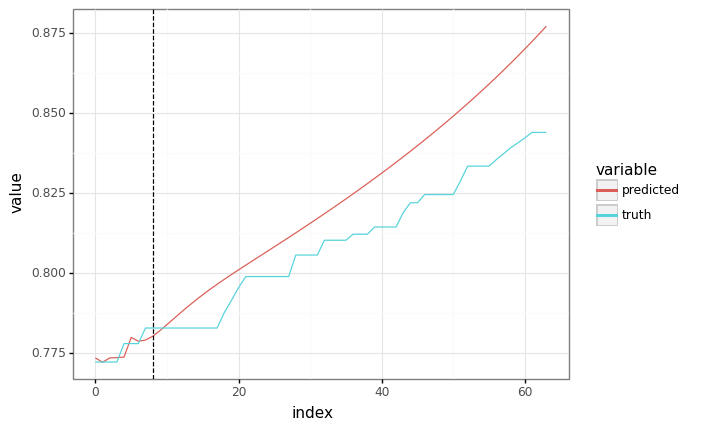
predicted = fast_autoregressive_predict(train_state.params, None, context, SEQ_LEN)
CPU times: user 24.6 s, sys: 54.8 ms, total: 24.6 s
Wall time: 24.6 s
# The plots should be equivalent!
plot = plot_samples(sample_y, predicted)
plot += gg.geom_vline(xintercept=context.shape[1], linetype="dashed")
_ = plot.draw()
Sample trajectories¶
sample_x, sample_y = next(valid_ds)
sample_x = sample_x[:1] # Shrink to batch-size 1.
sample_y = sample_y[:1] # Shrink to batch-size 1.
context_length = SEQ_LEN // 8
print(f"context_length = {context_length}")
# Cut the batch-size 1 context from the start of the sequence.
context = sample_x[:, :context_length]
# Reuse the same context from the previous cell.
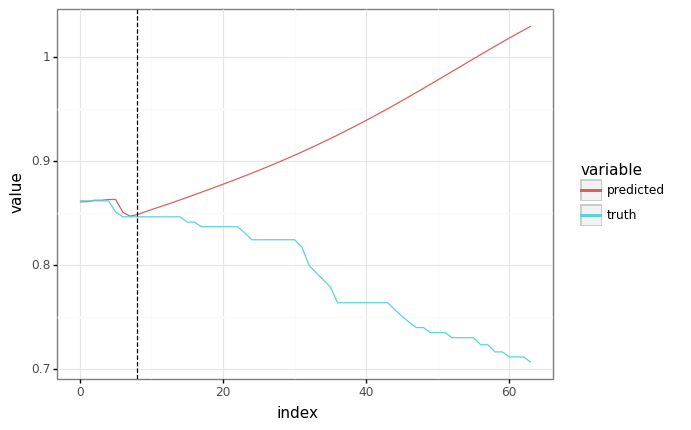
predicted = fast_autoregressive_predict(train_state.params, None, context, SEQ_LEN)
# The plots should be equivalent!
plot = plot_samples(sample_y, predicted)
plot += gg.geom_vline(xintercept=context.shape[1], linetype="dashed")
_ = plot.draw()
context_length = 8
timeit¶
%timeit autoregressive_predict(train_state.params, context, SEQ_LEN)
%timeit fast_autoregressive_predict(train_state.params, None, context, SEQ_LEN)
32.4 ms ± 331 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
25 µs ± 90.7 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Train all stars¶
Training¶
def split_train_validation_date(dataframe, date, look_back) -> TrainSplit:
train_size = len(dataframe.loc[:date])
return split_train_validation(dataframe, train_size, look_back)
%%time
train, valid = split_train_validation_date(dataframe_normed, TRAIN_DATE, SEQ_LEN)
print(f"effective train size = {train[0].shape[1]}")
838194 batches rounded to 524288 batches.
26455 batches rounded to 16384 batches.
effective train size = 64
CPU times: user 2.65 s, sys: 743 ms, total: 3.39 s
Wall time: 2.82 s
train[0].shape, train[1].shape, valid[0].shape, valid[1].shape
((524288, 64, 1), (524288, 64, 1), (16384, 64, 1), (16384, 64, 1))
train_ds = Dataset(train, BATCH_SIZE)
valid_ds = Dataset(valid, BATCH_SIZE)
# del train, valid # Don't leak temporaries.
%%time
train_state, records = train_model(
model_with_loss,
train_ds,
valid_ds,
len(train.x) // BATCH_SIZE * 1,
jax.random.PRNGKey(42),
record_freq=RECORD_FREQ,
)
End of the data set (size=524288). Return to the beginning.
CPU times: user 1min 30s, sys: 408 ms, total: 1min 30s
Wall time: 1min 30s
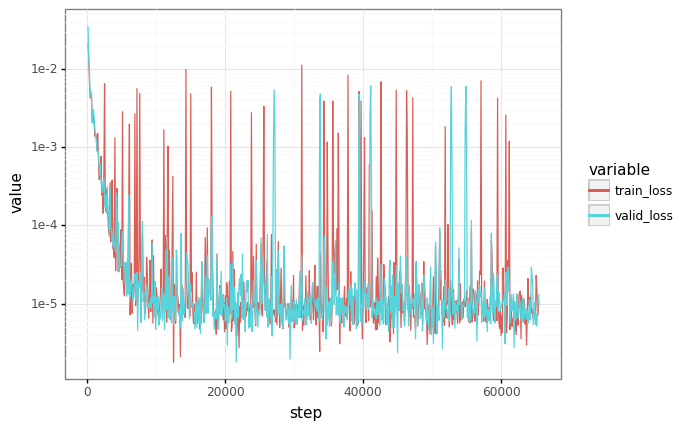
# Plot losses
losses = pd.DataFrame(records)
df = pd.melt(losses, id_vars=["step"], value_vars=["train_loss", "valid_loss"])
plot = (
gg.ggplot(df)
+ gg.aes(x="step", y="value", color="variable")
+ gg.geom_line()
+ gg.scales.scale_y_log10()
)
_ = plot.draw()
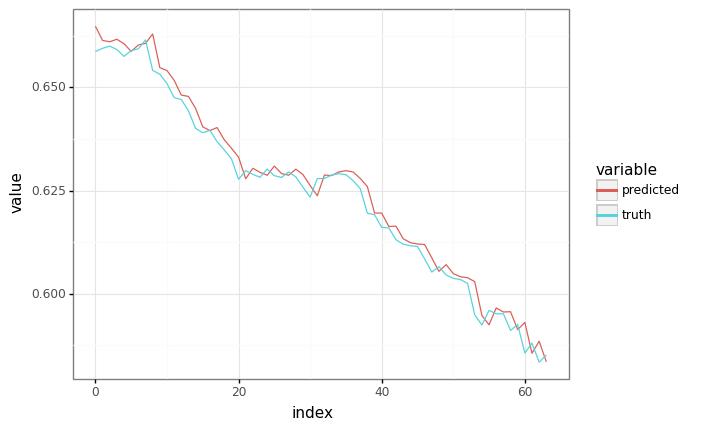
Sampling¶
# Grab a sample from the validation set.
sample_x, sample_y = next(valid_ds)
sample_x = sample_x[:1] # Shrink to batch-size 1.
sample_y = sample_y[:1] # Shrink to batch-size 1.
# Generate a prediction, feeding in ground truth at each point as input.
predicted, _ = model.apply(train_state.params, None, sample_x)
plot = plot_samples(sample_y, predicted)
_ = plot.draw()
Run autoregressively¶
%%time
sample_x, sample_y = next(valid_ds)
sample_x = sample_x[:1] # Shrink to batch-size 1.
sample_y = sample_y[:1] # Shrink to batch-size 1.
context_length = SEQ_LEN // 8
# Cut the batch-size 1 context from the start of the sequence.
context = sample_x[:, :context_length]
# Reuse the same context from the previous cell.
predicted = fast_autoregressive_predict(train_state.params, None, context, SEQ_LEN)
# The plots should be equivalent!
plot = plot_samples(sample_y, predicted)
plot += gg.geom_vline(xintercept=len(context), linetype="dashed")
_ = plot.draw()
CPU times: user 64.6 ms, sys: 2.56 ms, total: 67.2 ms
Wall time: 65.8 ms