# Uncomment to run the notebook in Colab
# ! pip install -q "wax-ml[complete]@git+https://github.com/eserie/wax-ml.git"
# ! pip install -q --upgrade jax jaxlib==0.1.70+cuda111 -f https://storage.googleapis.com/jax-releases/jax_releases.html
# check available devices
import jax
print("jax backend {}".format(jax.lib.xla_bridge.get_backend().platform))
jax.devices()
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
jax backend cpu
[CpuDevice(id=0)]
⏱ Synchronize data streams ⏱¶
![]()
Physicists, and not the least 😅, have brought a solution to the synchronization problem. See Poincaré-Einstein synchronization Wikipedia page for more details.
In WAX-ML we strive to follow their recommendations and implement a synchronization mechanism between different data streams. Using the terminology of Henri Poincaré (see link above), we introduce the notion of “local time” to unravel the stream in which the user wants to apply transformations. We call the other streams “secondary streams”. They can work at different frequencies, lower or higher. The data from these secondary streams will be represented in the “local time” either with the use of a forward filling mechanism for lower frequencies or a buffering mechanism for higher frequencies.
We implement a “data tracing” mechanism to optimize access to out-of-sync streams. This mechanism works on in-memory data. We perform the first pass on the data, without actually accessing it, and determine the indices necessary to later access the data. Doing so we are vigilant to not let any “future” information pass through and thus guaranty a data processing that respects causality.
The buffering mechanism used in the case of higher frequencies works with a fixed
buffer size (see the WAX-ML module
wax.modules.Buffer)
which allows us to use JAX / XLA optimizations and have efficient processing.
Let’s illustrate with a small example how wax.stream.Stream synchronizes data streams.
Let’s use the dataset “air temperature” with :
An air temperature is defined with hourly resolution.
A “fake” ground temperature is defined with a daily resolution as the air temperature minus 10 degrees.
import xarray as xr
dataset = xr.tutorial.open_dataset("air_temperature")
dataset["ground"] = dataset.air.resample(time="d").last().rename({"time": "day"}) - 10
Let’s see what this dataset looks like:
dataset
<xarray.Dataset>
Dimensions: (day: 730, lat: 25, lon: 53, time: 2920)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
* day (day) datetime64[ns] 2013-01-01 2013-01-02 ... 2014-12-31
Data variables:
air (time, lat, lon) float32 ...
ground (day, lat, lon) float32 231.9 231.8 231.8 ... 286.5 286.2 285.7
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...- day: 730
- lat: 25
- lon: 53
- time: 2920
- lat(lat)float3275.0 72.5 70.0 ... 20.0 17.5 15.0
- standard_name :
- latitude
- long_name :
- Latitude
- units :
- degrees_north
- axis :
- Y
array([75. , 72.5, 70. , 67.5, 65. , 62.5, 60. , 57.5, 55. , 52.5, 50. , 47.5, 45. , 42.5, 40. , 37.5, 35. , 32.5, 30. , 27.5, 25. , 22.5, 20. , 17.5, 15. ], dtype=float32) - lon(lon)float32200.0 202.5 205.0 ... 327.5 330.0
- standard_name :
- longitude
- long_name :
- Longitude
- units :
- degrees_east
- axis :
- X
array([200. , 202.5, 205. , 207.5, 210. , 212.5, 215. , 217.5, 220. , 222.5, 225. , 227.5, 230. , 232.5, 235. , 237.5, 240. , 242.5, 245. , 247.5, 250. , 252.5, 255. , 257.5, 260. , 262.5, 265. , 267.5, 270. , 272.5, 275. , 277.5, 280. , 282.5, 285. , 287.5, 290. , 292.5, 295. , 297.5, 300. , 302.5, 305. , 307.5, 310. , 312.5, 315. , 317.5, 320. , 322.5, 325. , 327.5, 330. ], dtype=float32) - time(time)datetime64[ns]2013-01-01 ... 2014-12-31T18:00:00
- standard_name :
- time
- long_name :
- Time
array(['2013-01-01T00:00:00.000000000', '2013-01-01T06:00:00.000000000', '2013-01-01T12:00:00.000000000', ..., '2014-12-31T06:00:00.000000000', '2014-12-31T12:00:00.000000000', '2014-12-31T18:00:00.000000000'], dtype='datetime64[ns]') - day(day)datetime64[ns]2013-01-01 ... 2014-12-31
array(['2013-01-01T00:00:00.000000000', '2013-01-02T00:00:00.000000000', '2013-01-03T00:00:00.000000000', ..., '2014-12-29T00:00:00.000000000', '2014-12-30T00:00:00.000000000', '2014-12-31T00:00:00.000000000'], dtype='datetime64[ns]')
- air(time, lat, lon)float32...
- long_name :
- 4xDaily Air temperature at sigma level 995
- units :
- degK
- precision :
- 2
- GRIB_id :
- 11
- GRIB_name :
- TMP
- var_desc :
- Air temperature
- dataset :
- NMC Reanalysis
- level_desc :
- Surface
- statistic :
- Individual Obs
- parent_stat :
- Other
- actual_range :
- [185.16 322.1 ]
[3869000 values with dtype=float32]
- ground(day, lat, lon)float32231.9 231.8 231.8 ... 286.2 285.7
array([[[231.89 , 231.79999, 231.79999, ..., 224.39 , 225.5 , 227.59999], [236.29999, 235.29999, 234.2 , ..., 220.89 , 221.5 , 224.5 ], [246.6 , 244.7 , 242.09999, ..., 220.7 , 221.79999, 226.09999], ..., [286.6 , 286.4 , 286. , ..., 286.5 , 285.79 , 285.29 ], [287. , 287.5 , 287.1 , ..., 286.79 , 286.6 , 286.29 ], [287.5 , 287.69998, 287.5 , ..., 287.79 , 288. , 287.9 ]], [[233.79999, 233.79999, 233.5 , ..., 230.89 , 232.7 , 234.59999], [237.59999, 237.7 , 237.29999, ..., 227.09999, 227.7 , 229.29999], [241.89 , 241.29999, 240.5 , ..., 229.39 , 230.5 , 233.09999], ... [286.59 , 285.88998, 285.29 , ..., 286.88998, 286.29 , 285.38998], [286.69 , 287.49 , 287.29 , ..., 286.69 , 286.29 , 285.59 ], [287.79 , 288.49 , 288.38998, ..., 287.38998, 286.88998, 286.09 ]], [[235.09 , 234.29 , 233.29 , ..., 231.68999, 231.48999, 231.79 ], [239.89 , 239.29 , 238.39 , ..., 229.59 , 230.29 , 231.68999], [252.98999, 252.19 , 251.38998, ..., 229.89 , 232.59 , 236.29 ], ..., [283.79 , 283.69 , 285.09 , ..., 285.29 , 285.09 , 284.69 ], [286.09 , 286.88998, 287.19 , ..., 285.69 , 285.69 , 285.19 ], [287.69 , 288.09 , 288.09 , ..., 286.49 , 286.19 , 285.69 ]]], dtype=float32)
- Conventions :
- COARDS
- title :
- 4x daily NMC reanalysis (1948)
- description :
- Data is from NMC initialized reanalysis (4x/day). These are the 0.9950 sigma level values.
- platform :
- Model
- references :
- http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanalysis.html
from wax.accessors import register_wax_accessors
register_wax_accessors()
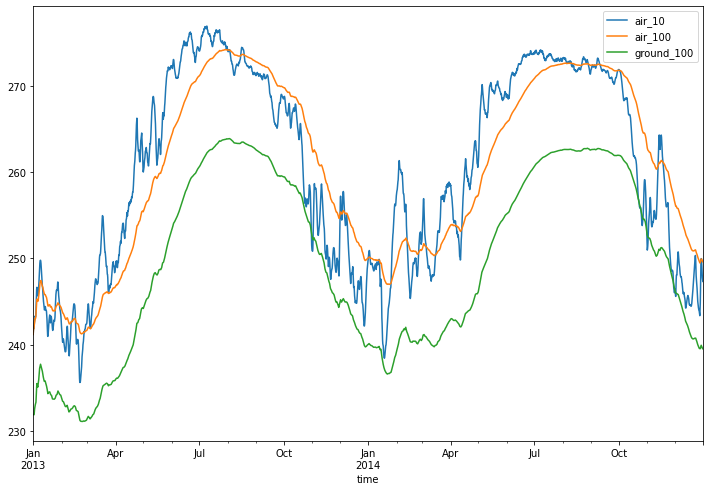
from wax.modules import EWMA
def my_custom_function(dataset):
return {
"air_10": EWMA(1.0 / 10.0)(dataset["air"]),
"air_100": EWMA(1.0 / 100.0)(dataset["air"]),
"ground_100": EWMA(1.0 / 100.0)(dataset["ground"]),
}
results, state = dataset.wax.stream(
local_time="time", ffills={"day": 1}, pbar=True
).apply(my_custom_function, format_dims=dataset.air.dims)
_ = results.isel(lat=0, lon=0).drop(["lat", "lon"]).to_pandas().plot(figsize=(12, 8))